
Anthropic 揭秘 AI 黑盒:理解模型內部的思考流程

你可能經常聽到:「AI 是一個黑盒子」這句話,我們知道輸入與輸出,卻難以理解其間的運作機制。這種不透明性不僅限制了 AI 的應用範圍,也引發了人們對於 AI 安全性與可靠性的擔憂。
Anthropic 近期的研究,旨在打破這個黑盒子,探索 AI 模型內部的思考流程,為提升 AI 的可解釋性與可控性開闢了新的道路。
黑盒子問題

AI 模型被比喻為黑盒子是因為:模型並非透過程式碼直接指定輸出,而是透過大量資料訓練。
並且在訓練中,他們學習到自己的策略去解決問題,但如果我們讓 AI 變得盡可能實用、可信賴並且安全,我們就需要打開那個黑盒子,並且真正瞭解他們在做的事。
探索神祕黑盒的新方法
如果我們只是打開那個黑盒子,就像神經學家赤裸裸得看著一顆大腦一樣,沒有任何幫助。我們需要工具去翻譯、解讀。
Anthropic 開發了一種新方法,得以觀察 AI 模型內部的思考流程,這項技術就像為神經科學家提供了解剖大腦的工具,讓我們可以對 AI 模型的思考方式進行研究。
以詩歌創作為例:He saw a carrot and had to grab it.
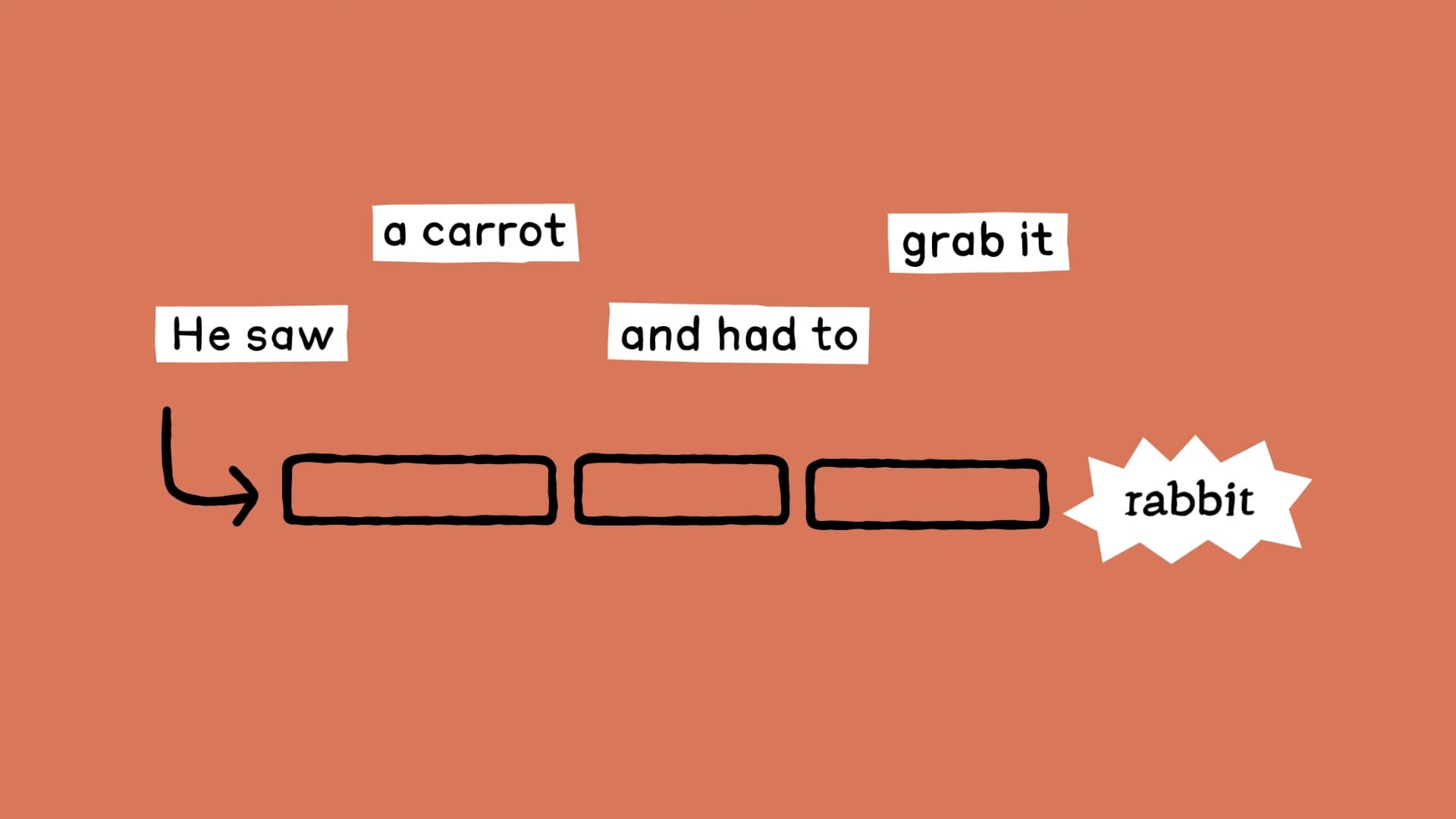
為了驗證這項新方法,Anthropic 的研究團隊利用 Claude 去創作這首詩的後半段。
研究人員發現,Claude 在構思第二句詩時,首先考慮的是尋找與第一句押韻的詞彙,甚至在寫出第二句的開頭之前,Claude 就已經在思考壓韻的可能性。
- Claude 看到 「a carrot」 以及 「grab it」 就想到 「rabbit」 這個合理並且壓韻的詞,
- 最終完成了「His hunger was like a starving rabbit.」這句詩
介入 AI 的思考流程
研究人員進一步發現,Claude 在構思詩句時,也曾考慮過「habit」這個詞。利用 Anthropic 開發的新方法,研究人員可以介入 Claude 的思考過程,並要求 Claude 以「habit」而非「rabbit」為基礎,重新構思第二句詩。
最終,Claude 產出了「His hunger was a powerful habit.」這句詩。
這個實驗結果表明,AI 模型並非只能按照既定的單一路線產生結果,而是能夠預先規劃,並尋求不同的方式來完成目標。
重要結論:AI 模型確實以其獨特的方式進行思考

Anthropic 的研究揭示了一個重要的結論:AI 模型確實以其獨特的方式進行思考。
正如神經科學的研究有助於治療疾病,提升人類健康,Anthropic 的長期目標是透過對 AI 更深入的理解,使其模型更加安全且值得信賴。如果我們能夠讀懂 AI 模型的思想,就能更有信心地確保它們以符合我們期望的方式運作。
解構 AI:是解放還是框架

在 Anthropic 成功解構 AI 模型內部思維的同時,我們不禁思考:當 AI 的思考不再是個黑盒子,一般使用者又能如何駕馭這份洞察?如果我們能理解 AI 在創作時會優先考量壓韻,或許就能調整 Prompt 的設計,使其更貼近 AI 的邏輯,進而產生更理想的內容。
然而,我們也必須深入思考:我們對 AI 的「理解」是否僅止於表象? 更甚者,在 AI 的「框架」愈發清晰的情況下,會不會趨於平衡,導致產出都變成預期內的產物?
一時半會間,我們或許還無法對這些問題給出明確的答案,但可以肯定的是,Anthropic 的研究指明了未來的道路,為我們帶來了更多想像空間。
https://www.anthropic.com/research/tracing-thoughts-language-model
Member discussion