
從 Prompt Engineering 到 Context Engineering
Prompt Engineering vs. Context Engineering
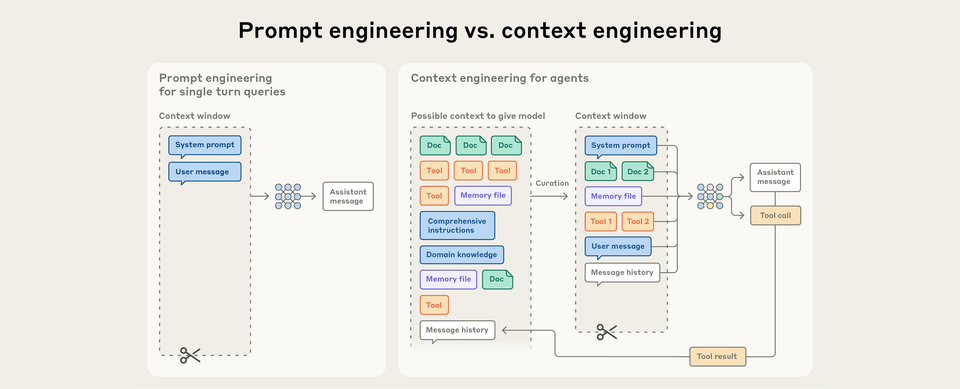
Prompt Engineering 的侷限
過去我們在跟 LLM 溝通時,最在乎的是 Prompt Engineering。
它的重點在於:如何寫出一個有效的 prompt,特別是 system prompt,好讓 LLM 一次就聽懂我們的指令,並且產出理想的結果。

隨著 LLM 的快速發展,我們透過 AI 執行的任務越來越複雜,需要的背景資料、使用的工具也隨之增長膨脹。
這時候,專注在單次、獨立任務的 Prompt Engineering,就逐漸不能滿足我們的需求了。
Context Engineering 的崛起

這裡必須先提到一個概念:AI Agents。
AI Agents 的簡單定義:
為了達成一個目標,主動思考、自主使用各種工具(如搜尋、讀取檔案、執行特定指令),並不斷循環這個過程直到任務完成的 LLMs。
就像真人助理一樣,我們不必把所有細節一次交代清楚。助理會根據自己的判斷去查資料、用工具,想辦法完成我們交辦的最終目標。
隨著 LLM 的能力提升,Agent 能夠:
- 操作更多輪推論
- 橫跨更長時間範圍
- 執行更複雜行為
我們需要的就不再只是單一的指令技巧,而是一套管理整個互動過程的策略。
Context Engineering 因應而生。
相較於 Prompt Engineering 專注於單次、獨立的任務,Context Engineering 則在每一次與 LLM 互動的過程迭代發生。
Context Engineering 實際上如何運作?

讓我們用一個任務來說明 Context Engineering 的運作模式:
我們的目標: 「幫我規劃一趟三天兩夜的東京家庭旅遊,兩個大人,喜歡美食跟動漫。」
AI Agent 的思考與行動過程,就是一場「Context 管理」的自主推理過程:
- 初始 Context: Agent 的工作記憶區裡,現在有了我們的目標:
{主題:東京旅遊, 天數:3天2夜, 人數:2, 興趣:美食、動漫}。 - 行動 1 (使用工具): Agent 判斷需要先解決交通。它執行
web_search("台北到東京來回機票價格")。 - 更新 Context: 工具回傳了搜尋結果,顯示廉價航空來回機票價格約為 NT$8,500 起。Agent 將這個新資訊加入 Context,現在它的工作記憶更新為:
{...舊有資訊..., 機票預算:TWD 17,000}。 - 行動 2 (推論與使用工具): Agent 根據更新後的 Context,推斷出住宿和活動的預算。接著它再次執行搜尋
web_search("東京新宿動漫主題飯店 兩人房價格")。 - 持續迭代: Agent 會不斷重複「根據當前 Context 思考 → 決定行動 → 使用工具 → 將新結果更新回 Context」這個循環,直到整個行程規劃完成。
在這個過程中,每一次的 Prompt 都是動態生成的,而管理和優化這一連串不斷變化的「對話歷史 + 工具結果 + 中間思考」,就是 Context Engineering 的核心。
為什麼我們需要 Context Engineering?

注意力預算(Attention Budget)
就像人腦有工作記憶容量,LLM 也一樣擁有類似的機制。Context 對於 LLM 來說也應該被視為有限量的資源,且會隨著數量的增加而邊際效應遞減。
這樣的機制帶出了一個概念:Context Rot,也就是在 token 數目增加時,model 對 context 內容準確回憶資訊的能力會顯著下降。
這種機制來自於二點:
- Transformer:LLM 背後架構
- 每個 token 會關注其他 token
- 耗費 n^2 的計算資源。
- LLM 注意力模式:模型訓練資料的分佈不均
- 較短的序列比長序列更為常見
- 處理跨 Context 的依賴關係時,經驗少且專門參數不足
這也是為什麼我們需要 Context Engineering:
精確地選擇最少量但資訊量高的 token,以最大化達成預期結果的可能性。
不如等更大的 Context Window?

這似乎是顯而易見的策略。
然而,在可預見的未來,各種大小的 context window 都可能面臨 Context Pollution 以及資訊相關性的問題。
儘管模型能力不斷提升,將 context 視為寶貴且有限的資源,仍然是建構可靠、有效的 Agent 的核心。
參考資料

Member discussion