Unboxing the black box: Anthropic developed a way to read AI model’s internal thinking
Anthropic breaks the "AI black box" barrier, revealing how AI prioritizes rhyming when composing poetry. This technology allows us to "read" AI thoughts, improving explainability and safety while opening new paths for AI development.

You may often hear the phrase: "AI is a black box." We know the input and output, but it's difficult to understand the operational mechanism in between. This opacity not only limits AI's application scope but also raises concerns about AI safety and reliability.
Anthropic's recent research aims to break open this black box, exploring the internal thought processes of AI models, paving a new path toward improving AI explainability and controllability.
The Black Box Problem

AI models are likened to black boxes because: models don't directly specify outputs through code, but rather through training on large amounts of data.
During training, they learn their own strategies to solve problems, but if we want to make AI as practical, reliable, and safe as possible, we need to open that black box and truly understand what they're doing.
New Methods for Exploring the Mysterious Black Box
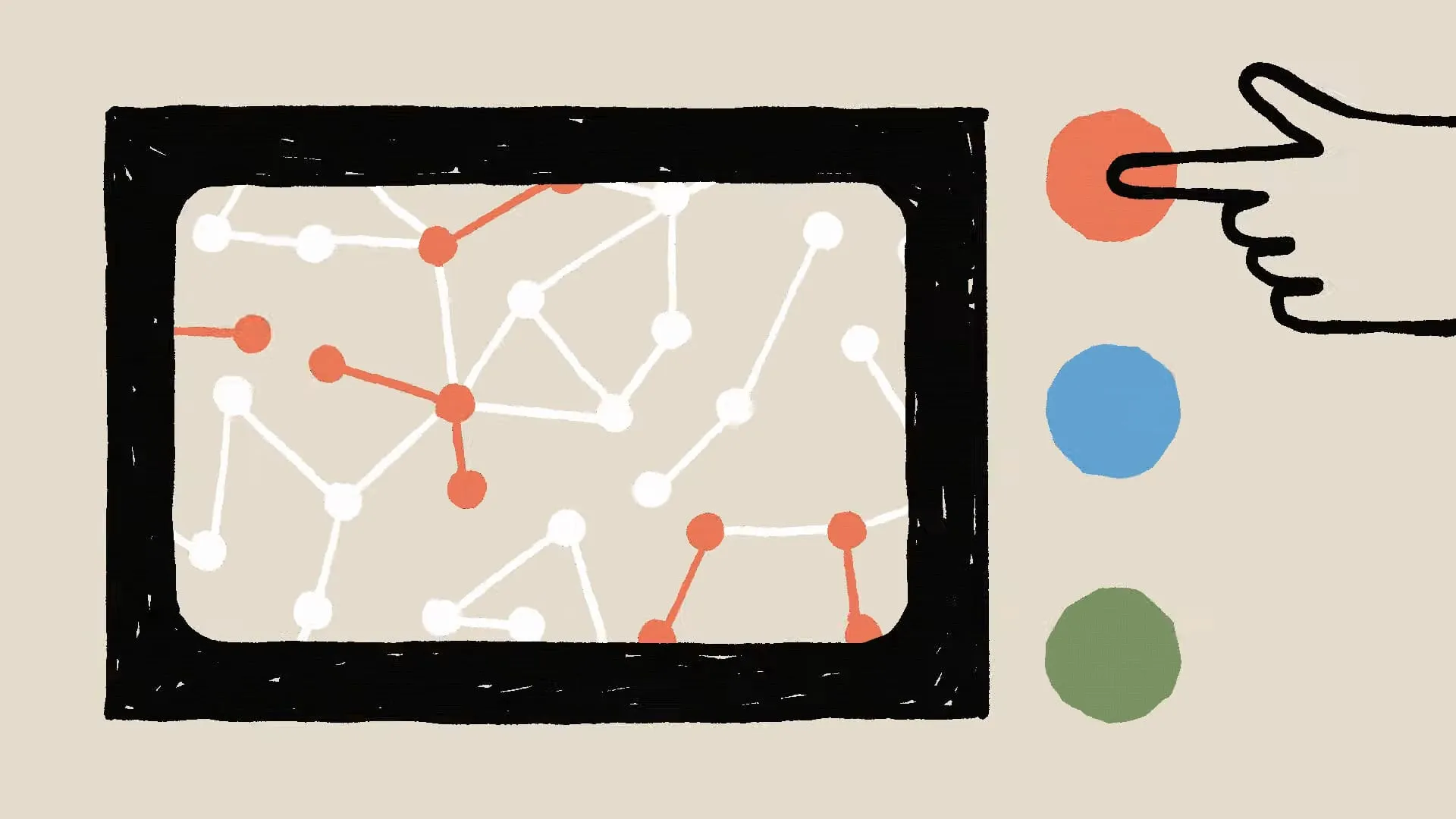
Simply opening the black box, like a neuroscientist looking at a brain without context, isn't helpful. We need tools to translate and interpret.
Anthropic has developed a new method that allows observation of AI models' internal thought processes. This technology is like providing neuroscientists with tools to dissect the brain, enabling us to study how AI models think.
Poetry Creation Example: "He saw a carrot and had to grab it."
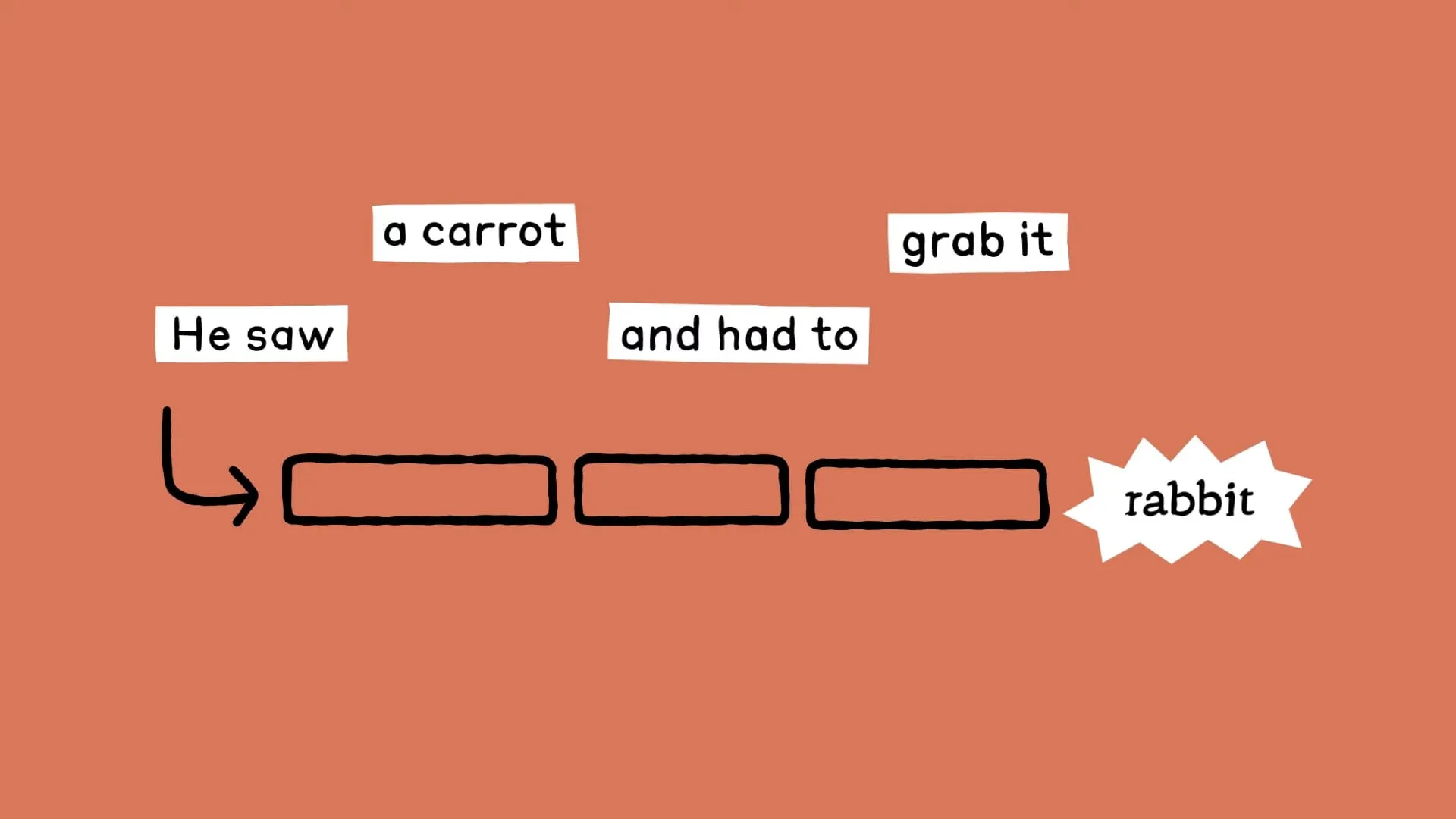
To verify this new method, Anthropic's research team used Claude to create the second half of this poem.
Researchers found that when composing the second line, Claude first considered finding words that rhymed with the first line, even before writing the beginning of the second line.
Claude saw "a carrot" and "grab it" and thought of "rabbit" as a reasonable and rhyming word, ultimately completing the poem with: "His hunger was like a starving rabbit."
Intervening in AI's Thought Process
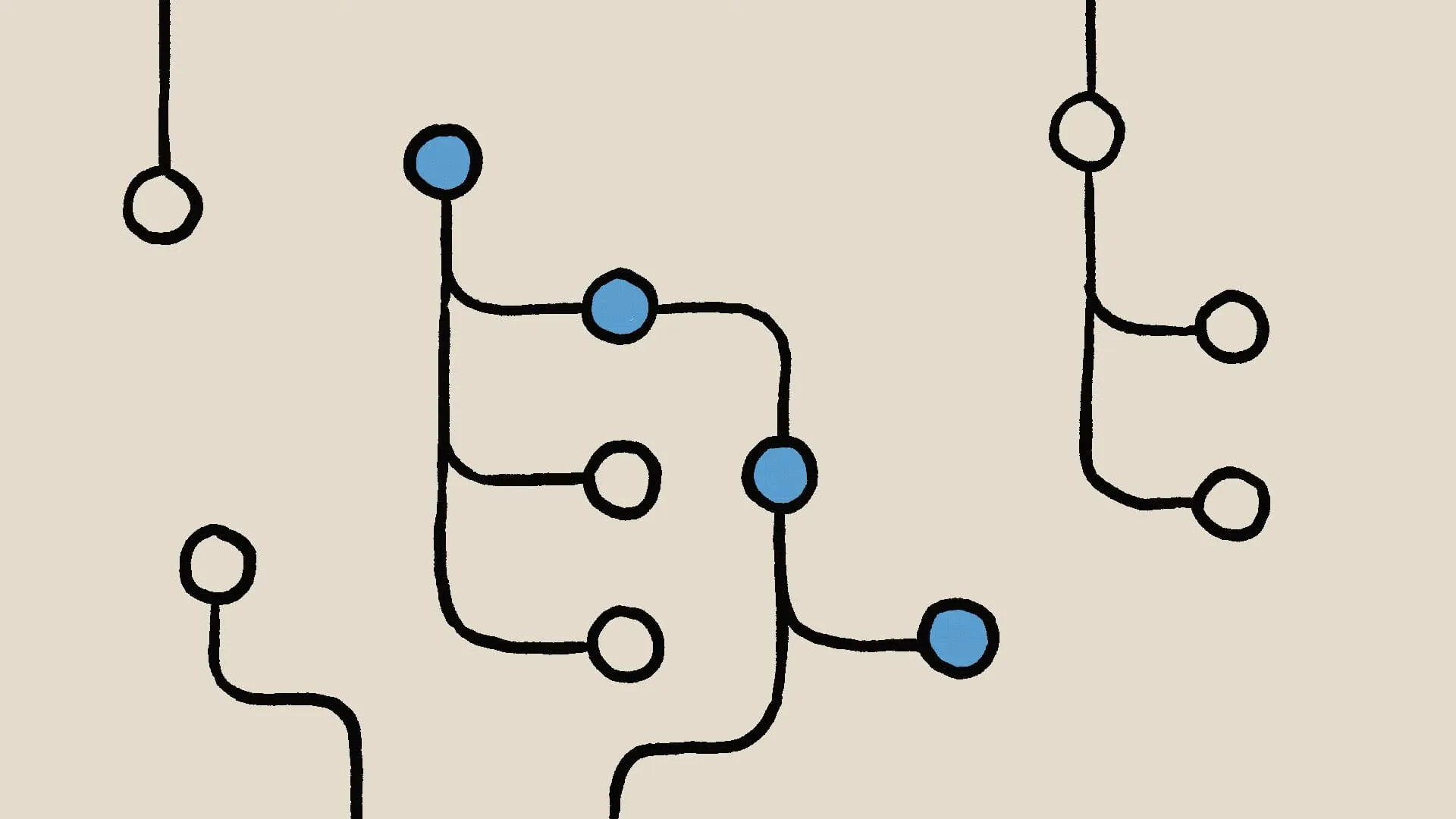
Researchers further discovered that Claude had also considered the word "habit" while composing the verse. Using Anthropic's new method, researchers could intervene in Claude's thinking process and ask Claude to reconsider the second line based on "habit" rather than "rabbit."
Eventually, Claude produced the line: "His hunger was a powerful habit."
This experimental result indicates that AI models aren't limited to producing results along a single predetermined path but can plan ahead and seek different ways to achieve goals.
Important Conclusion: AI Models Do Think in Their Unique Way

Anthropic's research reveals an important conclusion: AI models do think in their unique way.
Just as neuroscience research helps treat diseases and improve human health, Anthropic's long-term goal is to make their models safer and more trustworthy through a deeper understanding of AI. If we can read AI models' thoughts, we can be more confident in ensuring they operate in ways that meet our expectations.
Deconstructing AI: Liberation or Framework

While Anthropic successfully deconstructs the internal thinking of AI models, we can't help but wonder: how can ordinary users harness this insight when AI thinking is no longer a black box? If we understand that AI prioritizes rhyming during creation, perhaps we can adjust prompt design to better align with AI logic, thereby producing more ideal content.
However, we must also deeply consider: is our "understanding" of AI merely superficial? Moreover, as AI "frameworks" become increasingly clear, will we reach a balance where outputs become merely expected products?
For the time being, we may not have clear answers to these questions, but what's certain is that Anthropic's research points the way forward, bringing us more room for imagination.
https://www.anthropic.com/research/tracing-thoughts-language-model