From Prompt Engineering to Context Engineering
As AI Agents tackle increasingly complex tasks, traditional single-shot prompt engineering is no longer enough. Here's how Context Engineering emerges to work within the LLM's attention budget.
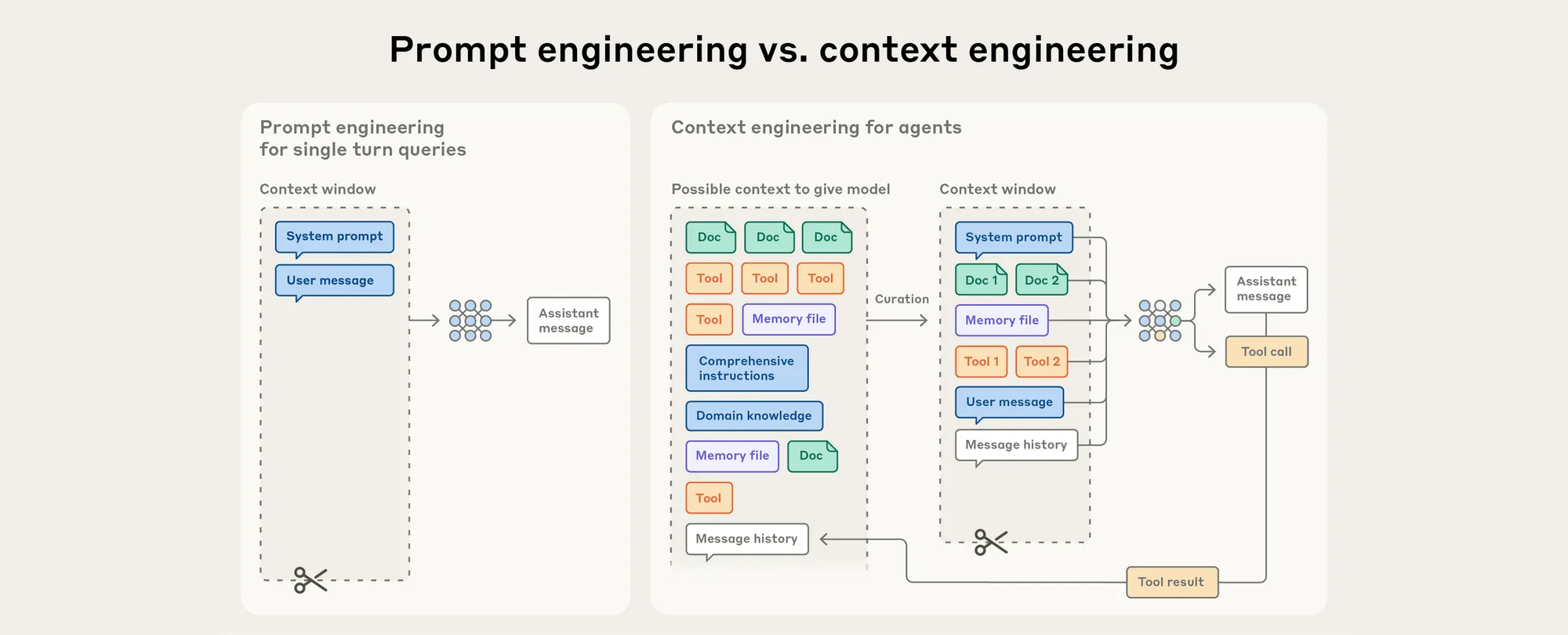
Prompt Engineering vs. Context Engineering
The Limits of Prompt Engineering
When we first started communicating with LLMs, our primary focus was on Prompt Engineering.
The goal was simple: how do you write an effective prompt — especially a system prompt — so the LLM understands your instructions on the first try and produces the result you're after?

As LLMs have rapidly evolved, the tasks we delegate to AI have grown far more complex, requiring more background context and a wider set of tools along the way.
At this point, Prompt Engineering — which focuses on single, isolated interactions — gradually stops meeting our needs.
The Rise of Context Engineering

To understand why, we first need to talk about AI Agents.
A simple definition of AI Agents:
LLMs that actively reason, autonomously use tools (such as web search, file reading, and executing specific commands), and repeat this cycle until a goal is achieved — all without requiring step-by-step instruction for every action.
Think of it like a human assistant. You don't need to spell out every detail upfront. The assistant uses their own judgment to look things up, use available tools, and find a way to accomplish the end goal you've given them.
As LLM capabilities have improved, Agents can now:
- Carry out more rounds of reasoning
- Operate across longer time horizons
- Execute more complex behaviors
What we need is no longer just a technique for crafting a single instruction — we need a strategy for managing the entire interaction.
Context Engineering emerged to fill that gap.
Whereas Prompt Engineering focuses on single, isolated tasks, Context Engineering operates iteratively across every exchange with the LLM.
How Does Context Engineering Actually Work?

Let's walk through a concrete example to illustrate how Context Engineering works in practice:
Our goal: "Plan a 3-day, 2-night family trip to Tokyo for two adults who love food and anime."
The AI Agent's thinking and action process is essentially an autonomous reasoning loop centered on managing context:
- Initial Context: The Agent's working memory now holds our goal:
{destination: Tokyo, duration: 3 days / 2 nights, travelers: 2, interests: food, anime}. - Action 1 (Tool Use): The Agent decides to tackle transportation first. It runs
web_search("Taipei to Tokyo round-trip airfare prices"). - Context Update: The tool returns results showing budget airline round-trip tickets starting around NT$8,500. The Agent adds this to its context:
{...previous info..., airfare budget: TWD 17,000}. - Action 2 (Reasoning + Tool Use): Based on the updated context, the Agent estimates the remaining budget for accommodation and activities, then runs another search:
web_search("Tokyo Shinjuku anime-themed hotel double room price"). - Continuous Iteration: The Agent keeps repeating the loop — "reason based on current context → decide on an action → use a tool → update context with new results" — until the full itinerary is complete.
Throughout this process, every prompt is dynamically generated. Managing and optimizing this ever-changing stream of conversation history + tool results + intermediate reasoning is the core of Context Engineering.
Why Do We Need Context Engineering?

The Attention Budget
Just as the human brain has a limited working memory capacity, LLMs operate under a similar constraint. Context should be treated as a finite resource — and one that exhibits diminishing returns as its size grows.
This dynamic gives rise to a concept called Context Rot: as the token count increases, a model's ability to accurately recall information from within its context degrades significantly.
This effect stems from two underlying factors:
- The Transformer architecture powering LLMs:
- Every token attends to every other token
- This consumes compute at O(n²) complexity
- LLM attention patterns shaped by training data distribution:
- Shorter sequences are far more common in training data than long ones
- Models have less experience — and fewer dedicated parameters — for handling dependencies that span a long context
This is precisely why Context Engineering matters:
Precisely selecting the minimum number of tokens with the highest information density, in order to maximize the likelihood of achieving the desired outcome.
Why Not Just Wait for a Bigger Context Window?

This might seem like the obvious solution.
However, for the foreseeable future, context windows of all sizes will remain susceptible to Context Pollution and issues around information relevance.
Even as model capabilities continue to improve, treating context as a precious and finite resource remains central to building reliable, effective Agents.
References
